



传统的监督学习在单个标签下进行学习, 即每个示例只与单个标签相关联, 已提出多种算法并取得良好了效果[1].然而, 现实世界中对象通常与多个标签同时关联.例如, 在图像分类中, 一幅图像可能同时包含树木、山地、日落等多个标签, 一首乐曲可能既属于“钢琴曲”又属于“古典音乐”, 蛋白质可能同时具有“运输”“免疫”等多种功能.因此, 给一个对象或示例赋予一个标签子集, 并且在此基础上进行建模和学习, 这就构成了多标签的学习框架, 使得每个示例与多个标签建立对应.多标签学习最初主要用于文本分类[2]研究, 随后被应用到一些新的领域,如音乐分类[3], 蛋白质功能分类[4]等.近年来在数据挖掘[5]、多媒体内容自动标注[6]、生物信息学[7]、信息检索[8]、个性化推荐[9]等方面得到广泛应用.如在音乐推荐方面, 通过多标签学习, 可以向用户推荐多个乐曲, 包括用户喜欢但不了解的音乐.可以看出, 多标签学习对于多义性对象的学习具有一定的意义, 已成为机器学习的研究热点之一.
二元关联(Binary Relevance,BR)[10]是最基本的一种多标签分类算法, 它假设标签之间相互独立, 把多标签分类问题转换为多个二分类问题, 方法简单, 易于实现, 但该算法未考虑标签之间的相关性.分类器链(Classifier Chain,CC)[11]把已分类标签加入到未分类标签的示例中训练, 从而克服在BR算法中不考虑标签相关性的缺点, 但CC算法是随机给一个序并按顺序将前一个标签当作此标签的属性, 虽然考虑了标签之间的相关性, 但由于是随机给定序, 不容易找到最优的顺序.集成分类器链(Ensembles of Classifier Chains,ECC)[11]在CC算法的基础上, 随机给定多个顺序, 然后对结果进行集成.尽管ECC算法通过集成学习来提高分类的效率, 但在处理集成多样性及标签序选择方面仍然存在一定缺陷.
在实际问题中, 标签之间并非完全独立, 是相互影响的.因此, 标签相关性对于多标签学习具有很大影响.目前, 有关标签相关性研究较少, 除CC算法外, 文献[12]提出了学习树加权模型的考虑标签相关的算法.文献[13]通过对分类器误差学习得到贝叶斯网结构, 提出与标签相关的多标签分类算法.本文考虑将标签集进行贝叶斯网学习, 找出与此标签最相关的父节点标签, 进而将父节点标签作为此标签的属性.
针对连续数据, 为了更好的分类, 通常采用离散化方法.目前, 绝大多数的离散化算法只针对单标签数据集, 常见的有等距离算法和等频率算法[14]以及Ching[15]等提出的CDDA(Class-Dependent Discretizer Algorithm), Cios等[16]提出的CAIM(Class-Attribute Interdependence Maximization)算法.本文针对多标签数据集, 提出一种连续数据离散化的MLAIM(Multi-Label Attribute Interdependence Maximization)算法.在此基础之上, 提出MLLD(Multi-Label classification algorithm based on Label Dependency)算法, 并通过典型多标签数据集对所给算法与其他多标签分类算法进行对比分析.
1 MLAIM离散化算法考虑一个数据集包含M个示例和s个标签, 将连续属性a划分为n个区间Q={[d0, d1], [d1, d2], …, [dn-1, dn]}, 其中d0 < d1 < d2 < … < dn, 得到决策表, 见表 1.
| 决策类 | 区间 | 合计 | ||||
| [d0, d1] | … | (dr-1, dr] | … | (dn-1, dn] | ||
| y1 | q11 | … | q1r | … | q1n | 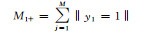
|
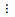
|
|
… |
|
… |
|
|
| yi | qi1 | … | qir | … | qin | 
|
|
|
… | |
… | |
|
| ys | qs1 | … | qsr | … | qsn | 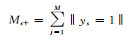
|
| 合计 | M+1 | … | M+r | … | M+n | 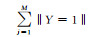
|
表 1中qir(i=1, 2, …, S; r=1, 2, …, n)表示示例中属于第i类并且属于区间[dr-1, dr]的个数, yi={1, -1}, ‖yi=1‖表示属于标签yi的示例个数, ‖Y=1‖表示属于标签Y的示例总个数.
MLAIM算法是以最大化类与属性之间的相关性并最小化断点数为目标, 考虑到一个示例可能属于多个标签, 取同区间中最大和次大的进行计算, 以I值作为判别式, 即
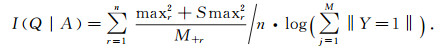
|
其中maxr表示所有qir中的最大值, Smaxr表示所有qir中的次大值, n表示断点个数.通过最大化I值, 得到最优的离散数据.
MLAIM算法依次对每个连续属性进行离散化, 离散过程中只需输入标签个数、示例数据集及其对应标签.离散过程中, 首先将global I置为0, 并计算每一个候选断点的I值, 再找出最大的I值与global I值比较, 如果I>global I或者r < s(r表示已经添加的断点个数, s表示类标签的个数), 则将此断点加入到离散断点集合中, 并将此I值赋给global I, 重复此过程; 否则, 结束.依次对连续属性进行离散, 直至全部结束.
MLAIM算法步骤如下:
Step 1 输入:数据集Dm×n(此数据集具有m个示例, t个连续属性, s个类标签, n=t+s), 连续属性集A, 类标签个数s;
Step 2 for i=1, 2, …, t;
Step 3 初始化;
Step 4 在连续属性Ai中, 找出最大值xn+1和最小值x0;
Step 5 将连续属性Ai中的值从小到大排列{x0, x1, …, xn, xn+1};
Step 6 计算候选断点 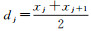
Step 7 初始化候选断点集合B{d0, d1, d2, …, dn-1, dn};
Step 8 初始化断点集合Q=[d0, dn];
Step 9 初始化global I=0, r=1;
Step 10 离散化;
Step 11 for j=1:n;
Step 12 将候选断点集中的断点dj加入到断点集合Q中, 并计算加入后的I值;
Step 13 选出I值最大的断点dx;
Step 14 end for (Step 11);
Step 15 if I>global I或者r < s;
Step 16 令global I=Imax, r=r+1;
Step 17 将候选断点dx加入到断点集合Q中;
Step 18 else跳出循环;
Step 19 end if;
Step 20 返回到Step 11;
Step 21 end for (Step 2);
Step 22 输出:离散化断点集合Q.
2 MLLD算法朴素贝叶斯模型又称朴素贝叶斯分类器, 是包含一个根节点和多个叶节点的树状贝叶斯网, 如图 1所示.其中叶节点是属性变量, 根节点是类变量.用朴素贝叶斯模型分类就是给定一个示例, 计算同一示例不同类别的概率P(类别|示例), 然后选择概率最大的那个类别作为这个示例的所属类别.

|
| 图 1 朴素贝叶斯分类器 Fig.1 Navie bayes classifier |
MLLD算法首先是对训练标签集进行贝叶斯网结构学习(本文用K2算法[17], 它是最早的贝叶斯网结构学习算法之一), 得到标签集的贝叶斯网结构及其拓扑序,即见MLLD算法1.MLLD算法1步骤如下:
Step 1 输入:训练集中对应的标签集Y=(y1, y2, …, yq), 初始序列order;
Step 2 P←[];
Step 3 用贝叶斯网结构学习中的K2算法学得贝叶斯网DAG←K2(Y, order);
Step 4 for i∈{1, 2, …, q};
Step 5 在DAG中找出对应节点的父节点P(i)←parents(DAG(i));
Step 6 end for;
Step 7 输出:父节点P.
其次将数据集进行离散化, 即MLAIM算法.最后利用二类分类思想将朴素贝叶斯分类器作为基分类器, 训练过程中将待分类标签的父节点标签集加入到训练示例中进行训练, 输入测试示例进行预测, 即MLLD算法2.MLLD算法2步骤如下:
训练过程:
Step 1 输入:训练集D={(X1, Y1), (X2, Y2), …, (Xm, Ym)}, 其中Y:m×q; 测试示例(Xt);
Step 2 利用算法1可得标签父节点集合P及其拓扑序order;
Step 3 traininstance←[];
Step 4 for i∈{1, 2, …, q};
Step 5 将第i个标签的父节点标签集加入到训练示例中, traininstance←[X, train-label(P(order(i)))];
Step 6 label←train-label(order(i));
Step 7 用朴素贝叶斯分类器学习, Mdl(i)←naivebayes(traininstance, label);
Step 8 end for;
预测过程:
Step 9 Prelabel←[];
Step 10 for i∈{1, 2, …, q};
Step 11 将预测的第i个标签的父节点标签集加入到测试示例中, testinstance←[Xt, Prelabel(P(order(i)))];
Step 12 Prelabel(order(i))←predict(Mdl(i), testinstance);
Step 13 end for;
Step 14 输出:Prelabel.
上述算法过程可以描述如下。设q=5, 通过MLLD算法1可以得到如图 2所示的结构, 拓扑序order=(1, 2, 3, 4, 5), 则对应的父节点分别为P(1)=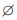

|
| 图 2 贝叶斯网结构 Fig.2 Bayesian network |

|
| 图 3 y5的贝叶斯网结构 Fig.3 Bayesian network of y5 |
实验采用Windows 7, Matlab 2015b操作系统.选取4个连续数据集(见表 2), 分别与BR[10]、CC[11]、ECC[11]、ML-kNN[18]、ML-RBF[19]、BP-MLL[20]、Rank-SVM[21]7种算法进行比较, 其中BR、CC、ECC基分类器为SVM.本文提出的MLLD算法采用离散化数据, 基分类器为朴素贝叶斯分类器.
| 数据集 | 训练示例数 | 预测示例数 | 特征数 | 标签数 | 标签基数 |
| scene | 1 211 | 1 196 | 294 | 6 | 1.074 |
| yeast | 1 500 | 917 | 103 | 14 | 4.327 |
| emotions | 391 | 202 | 72 | 6 | 1.868 |
| image | 400 | 200 | 294 | 5 | 1.235 |
已知多标签分类器h:X→2q以及多标签测试集T={(xi, Yi)|1≤i≤p}, 其中Yi表示隶属于实例xi的相关标签集合, q表示标签个数, 采用如下9种评价指标.
(1) 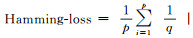
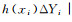

(3) 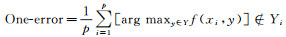
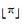
(4) 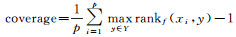
(5) 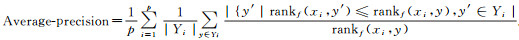
(6) 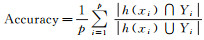
(7) 
(8) 


(9) 

表 3~6给出了各多标签学习算法在scene、yeast、emotions、image 4个数据集上的实验结果.
| 算法 | BR | CC | ECC | ML-kNN | ML-RBF | BP-MLL | Rank-SVM | MLLD |
| Hamming-loss | 0.113 6 | 0.127 0 | 0.100 5 | 0.098 9 | 0.094 6 | 0.289 4 | 0.122 8 | 0.155 5 |
| Ranking-loss | 0.102 6 | 0.134 0 | 0.1769 | 0.093 1 | 0.0795 | 0.389 1 | 0.0850 | 0.086 9 |
| One-error | 0.278 4 | 0.337 0 | 0.236 6 | 0.242 5 | 0.231 6 | 0.826 9 | 0.260 9 | 0.197 3 |
| coverage | 0.623 7 | 0.784 3 | 0.648 0 | 0.568 6 | 0.49 92 | 2.0410 | 0.534 3 | 0.484 9 |
| Average-precision | 0.828 6 | 0.790 7 | 0.836 4 | 0.851 2 | 0.862 0 | 0.464 6 | 0.845 3 | 0.863 8 |
| Accuracy | 0.576 2 | 0.630 9 | 0.688 1 | 0.629 3 | 0.591 4 | 0.167 4 | 0.519 8 | 0.568 3 |
| Recall | 0.632 9 | 0.654 3 | 0.710 7 | 0.654 7 | 0.602 8 | 0.168 9 | 0.609 9 | 0.844 1 |
| Micro-F1 | 0.665 0 | 0.646 8 | 0.713 8 | 0.698 6 | 0.692 3 | 0.166 9 | 0.638 5 | 0.658 9 |
| Macro-F1 | 0.669 7 | 0.645 6 | 0.721 3 | 0.691 6 | 0.696 2 | 0.050 8 | 0.643 7 | 0.678 2 |
| 算法 | BR | CC | ECC | ML-kNN | ML-RBF | BP-MLL | Rank-SVM | MLLD |
| Hamming-loss | 0.209 6 | 0.232 7 | 0.208 7 | 0.293 7 | 0.268 2 | 0.317 7 | 0.311 9 | 0.243 4 |
| Ranking-loss | 0.164 2 | 0.192 3 | 0.265 7 | 0.282 9 | 0.255 6 | 0.458 9 | 0.3164 | 0.186 4 |
| One-error | 0.267 3 | 0.336 6 | 0.247 5 | 0.405 9 | 0.396 0 | 0.524 8 | 0.509 9 | 0.331 7 |
| coverage | 1.861 4 | 1.950 5 | 2.133 7 | 2.490 1 | 2.331 7 | 3.257 4 | 2.549 5 | 1.955 4 |
| Average-precision | 0.807 1 | 0.774 8 | 0.780 4 | 0.693 8 | 0.718 4 | 0.591 8 | 0.657 9 | 0.768 0 |
| Accuracy | 0.509 9 | 0.521 5 | 0.526 8 | 0.319 3 | 0.332 5 | 0.052 0 | 0.383 7 | 0.524 2 |
| Recall | 0.585 0 | 0.631 2 | 0.622 1 | 0.377 1 | 0.373 8 | 0.052 0 | 0.506 6 | 0.732 7 |
| Micro-F1 | 0.648 2 | 0.640 3 | 0.643 1 | 0.457 3 | 0.471 5 | 0.085 5 | 0.519 1 | 0.660 7 |
| Macro-F1 | 0.624 5 | 0.633 5 | 0.612 3 | 0.385 3 | 0.411 8 | 0.050 8 | 0.520 7 | 0.652 7 |
| 算法 | BR | CC | ECC | ML-kNN | ML-RBF | BP-MLL | Rank-SVM | MLLD |
| Hamming-loss | 0.199 1 | 0.212 0 | 0.208 1 | 0.198 0 | 0.201 0 | 0.208 8 | 0.201 3 | 0.249 3 |
| Ranking-loss | 0.200 3 | 0.234 6 | 0.275 6 | 0.171 5 | 0.178 5 | 0.175 2 | 0.170 8 | 0.210 0 |
| One-error | 0.239 9 | 0.356 6 | 0.199 6 | 0.234 5 | 0.247 5 | 0.237 7 | 0.227 9 | 0.287 9 |
| coverage | 7.120 0 | 7.966 2 | 7.197 4 | 6.414 4 | 6.527 8 | 6.424 2 | 6.405 7 | 6.913 8 |
| Average-precision | 0.746 1 | 0.707 2 | 0.729 9 | 0.758 5 | 0.753 6 | 0.750 0 | 0.758 3 | 0.710 2 |
| Accuracy | 0.497 7 | 0.513 0 | 0.540 8 | 0.492 0 | 0.505 8 | 0.518 3 | 0.523 8 | 0.460 9 |
| Recall | 0.570 2 | 0.617 2 | 0.669 7 | 0.549 1 | 0.583 3 | 0.644 4 | 0.635 2 | 0.593 2 |
| Macro -F1 | 0.630 7 | 0.633 4 | 0.655 7 | 0.625 0 | 0.633 5 | 0.645 0 | 0.651 8 | 0.585 9 |
| Macro-F1 | 0.323 5 | 0.357 1 | 0.360 8 | 0.336 1 | 0.376 8 | 0.339 2 | 0.360 4 | 0.3868 |
| 算法 | BR | CC | ECC | ML-kNN | ML-RBF | BP-MLL | Rank-SVM | MLLD |
| Hamming-loss | 0.197 0 | 0.214 0 | 0.190 0 | 0.213 0 | 0.198 0 | 0.341 0 | 0.202 0 | 0.214 0 |
| Ranking-loss | 0.202 9 | 0.220 0 | 0.284 6 | 0.233 3 | 0.190 0 | 0.497 1 | 0.190 8 | 0.175 0 |
| One-error | 0.360 0 | 0.415 0 | 0.325 0 | 0.435 0 | 0.355 0 | 0.735 0 | 0.375 0 | 0.325 0 |
| coverage | 1.095 0 | 1.160 0 | 1.105 0 | 1.215 0 | 1.060 0 | 2.290 0 | 1.055 0 | 0.990 0 |
| Average-precision | 0.767 4 | 0.739 2 | 0.767 0 | 0.721 4 | 0.774 8 | 0.496 0 | 0.762 8 | 0.779 8 |
| Accuracy | 0.408 3 | 0.512 5 | 0.563 3 | 0.378 3 | 0.376 7 | 0.202 2 | 0.493 3 | 0.549 2 |
| Recall | 0.460 8 | 0.550 8 | 0.625 8 | 0.384 2 | 0.401 7 | 0.211 7 | 0.610 8 | 0.750 8 |
| Micro-F1 | 0.527 6 | 0.552 3 | 0.613 8 | 0.463 5 | 0.489 7 | 0.237 1 | 0.594 4 | 0.627 2 |
| Macro-F1 | 0.518 7 | 0.531 2 | 0.600 7 | 0.431 0 | 0.472 8 | 0.107 7 | 0.593 7 | 0.628 1 |
由表 3~6可以看出, 在scene数据集上, 本文提出的MLLD算法在One-error、coverage、Average-precision、Recall上均优于其他算法;在emotions数据集上, 本文提出的MLLD算法在Recall、Micro-F1、Macro-F1上优于其他算法.在yeast数据集上, 本文提出的MLLD算法只有在Macro-F1上优于其他算法, 其余各项指标都比较差;在image数据集上, 本文提出的MLLD算法除Hamming-loss、Accuracy外, 其余各项指标均优于其他算法.
根据表 3~6的结果, 在4个数据集上对8种算法的Hamming-loss根据测试性能由好到坏排序, 并赋予序值1, 2, 3, 4, 5, 6, 7, 8.若不同算法性能相同则平分序值, 求出每种算法在4个数据集上的Hamming-loss平均序值, 如表 7所示.对其余指标分别求出其在不同算法上的平均序值,并求出在9个指标的总序值.序值越小, 算法性能越好, 由表 8可知, 本文提出的MLLD算法的总序值只比ECC的大, 说明该算法总体性能要优于除ECC之外的6种分类器.
| 算法 | BR | CC | ECC | ML-kNN | ML-RBF | BP-MLL | Rank-SVM | MLLD |
| scene | 4 | 6 | 3 | 2 | 1 | 8 | 5 | 7 |
| emotions | 2 | 3 | 1 | 6 | 5 | 8 | 7 | 4 |
| yeast | 2 | 7 | 5 | 1 | 3 | 6 | 4 | 8 |
| image | 2 | 6.5 | 1 | 5 | 3 | 8 | 4 | 6.5 |
| 平均序值 | 2.5 | 5.625 | 2.5 | 3.5 | 3 | 7.5 | 5 | 6.375 |
| 算法 | BR | CC | ECC | ML-kNN | ML-RBF | BP-MLL | Rank-SVM | MLLD |
| Hamming-loss | 2.5 | 5.625 | 2.5 | 3.5 | 3 | 7.5 | 5 | 6.375 |
| Ranking-loss | 3.75 | 5.25 | 6.75 | 4.5 | 2.75 | 6.75 | 3.25 | 3 |
| One-error | 4.25 | 6.25 | 1.625 | 5 | 4 | 7 | 4.75 | 3.125 |
| coverage | 5 | 5.75 | 5.5 | 4.75 | 3.5 | 6.75 | 3.25 | 2.5 |
| Average-precision | 3.75 | 6 | 4.25 | 4.25 | 3 | 7 | 4.5 | 3.25 |
| Accuracy | 5 | 3 | 1 | 5.75 | 5.5 | 6.75 | 4.5 | 4.5 |
| Recall | 5.25 | 3.5 | 2 | 7.25 | 6.25 | 6.5 | 4.25 | 2 |
| Micro-F1 | 4.25 | 4.75 | 1.75 | 5.75 | 4.75 | 6.75 | 4.25 | 3.75 |
| Macro-F1 | 5.25 | 4.75 | 2.5 | 6 | 4 | 7.5 | 4.75 | 1.75 |
| 各分类器总序值 | 39 | 44.875 | 27.875 | 46.75 | 36.75 | 62.5 | 38. 5 | 30.25 |
针对CC算法中链的随机性, 不能将与此标签最相关的标签作为属性.因此将标签集进行贝叶斯网学习, 并将父节点作为标签的属性节点, 从而建立与标签相关的多标签分类模型,通过实验也充分说明此种方法的有效性.下一步考虑用标签的马尔克夫边界代替父节点作为标签的属性节点, 如此可将与此标签相关的其它标签均考虑到.
| [1] | MITCHELL T M. Machine learning[M]. New York: McGraw-Hill, 1997. |
| [2] | GAO S, WU W, LEE C H, et al.A MFoM learning approach to robust multiclass multi-label text categorization[C]//International Conference on Machine Learning.ACM, 2004:42. |
| [3] | LI T, OGIHARA M. Toward intelligent music information retrieval[J]. IEEE Trans on Multimedia, 2006, 8(3): 564-574 DOI:10.1109/TMM.2006.870730 |
| [4] | ZHANG M L, ZHOU Z H. Multi-label neural networks with applications to functional genomics and text categorization[J]. IEEE Trans on Knowledge and Data Engineering, 2006, 18(10): 1338-1351 DOI:10.1109/TKDE.2006.162 |
| [5] | LI P, WU X, HU X, et al. An incremental decision tree for mining multilabel data[J]. Applied Artificial Intelligence, 2015, 29(10): 992-1014 DOI:10.1080/08839514.2015.1097154 |
| [6] | SNOEK C G M, WORRING M, GEMERT J C, et al.The challenge problem for automated detection of 101 semantic concepts in multimedia[C]//ACM International Conference on Multimedia.ACM, 2006:421-430. |
| [7] | BARUTCUOGLU Z, SCHAPIRE R E, TROYANSKAYA O G. Hierarchical multi-label prediction of gene function[J]. Bioinformatics, 2006, 22(7): 830-836 DOI:10.1093/bioinformatics/btk048 |
| [8] | GOPAL S, YANG Y.Multilabel classification with meta-level features[C]//International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM, 2010:315-322. |
| [9] | SONG Y, ZHANG L, GILES L C.A sparse Gaussian processes classification framework for fast tag suggestions[C]//CIKM'08 Proceedings of the 17th ACM Conference on Information and Knowledge Management.Napa Valley.2008:93-102. |
| [10] | ZHANG M L, ZHOU Z H. A review on multi-label learning algorithms[J]. IEEE Transaction on Knowledge and Data Engineering, 2014, 26(8): 1819-1837 DOI:10.1109/TKDE.2013.39 |
| [11] | READ J, PFAHRINGER B, HOLMES G, et al. Classifier chains for multi-label classification[J]. Machine Learning, 2011, 85(3): 333-359 DOI:10.1007/s10994-011-5256-5 |
| [12] | ENRIQUE S L, BIELZA C, MORALES E F, et al. Multi-label classification with Bayesian network-based chain classifiers[J]. Pattern Recognition Letters, 2014, 41(1): 14-22 |
| [13] | ZHANG M L, ZHANG K.Multi-label learning by exploiting label dependency[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM, 2010:999-1008. |
| [14] | CHIU D, WONG A, CHEUNG B.Information discovery through hierarchical maximum entropy discretization and synthesis[C]//Proceedings of association for the advancement of artificial intelligence 91, CA:AAAI Press, 1991. |
| [15] | CHING J Y, WONG A K C, CHAN K C C. Class-dependent discretization for induction learning from continuous and mixed mode data[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1995, 17(7): 641-651 DOI:10.1109/34.391407 |
| [16] | CIOS K J, KURGAN L. CAIM discretization algorithm[J]. IEEE Transactions on Knowledge and Data Engineering, 2004, 16(2): 145-153 DOI:10.1109/TKDE.2004.1269594 |
| [17] | COOPER G F, HERSKOVITS E. A Bayesian method for the induction of probabilistic networks from data[J]. Machine Learning, 1992, 9(4): 309-347 |
| [18] | ZHANG M L, ZHOU Z H. ML-kNN:A lazy learning approach to multilabel learning[J]. Pattern Recognition, 2007, 40(7): 2038-2048 DOI:10.1016/j.patcog.2006.12.019 |
| [19] | ZHANG M L. ML-RBF:RBF neural networks for multi-label learning[J]. Neural Processing Letters, 2009, 29(2): 61-74 DOI:10.1007/s11063-009-9095-3 |
| [20] | ZHANG M L, ZHOU Z H. Multilabel neural networks with applications to functional genomics and text categorization[J]. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(10): 1338-1351 DOI:10.1109/TKDE.2006.162 |
| [21] | ELISSEEFF A, WESTON J.A kernel method for multi-labelled classification[C]//International Conference on Neural Information Processing Systems:Natural and Synthetic.Massachusetts:MIT Press, 2001:681-687. |